在 SEO 的世界中,了解正在优化的系统非常重要。
您需要了解如何:
- 搜索引擎抓取和索引网站。
- 搜索算法功能。
- 搜索引擎将用户意图视为排名信号(以及他们可能会使用它的地方)。
另一个需要理解的关键领域是机器学习。
现在, “机器学习”这个词现在被广泛使用。
但是机器学习实际上是如何影响搜索和搜索引擎优化的呢?
什么是机器学习?
如果不知道机器学习到底是什么,就很难理解搜索引擎如何使用机器学习。
机器学习:机器学习(ML) 是人工智能(AI) 的一部分,属于计算科学领域,专门分析和解释数据的模式及结构,以实现无需人工交互即可完成学习、推理和决策等行为的目的。
机器学习与人工智能 (AI) 不同,机器学习是一门让计算机根据信息得出结论的科学,但没有专门针对如何完成所述任务进行编程。人工智能是创建具有或似乎拥有类似人类智能并以类似方式处理信息的系统背后的科学。
可以这么思考:
机器学习是一种旨在解决问题的系统。它以数学方式工作以产生解决方案。
解决方案可以专门编程,也可以由人工手动制定,但如果没有这种需要,可能会更快就可以解决。
一个很好的例子是启动一台机器,通过大量概述某种疾病的数据,而无需编程它正在寻找的内容。机器会得到一份已知这个疾病结论的列表。
有了这个,我们会要求系统生成一个预测模型,用于未来与某种疾病重叠的机率,以提前生成基于分析数据的可能性,这纯粹是数学上的。
几百名数学家可以做到这一点——但这需要他们很多年(假设这是一个非常大的数据库),并且希望他们都不会犯任何错误。
或者,同样的任务可以通过机器学习来完成——在更短的时间内完成。另一方面,当我想到人工智能时,我开始想到一个涉及创意的系统,因此变得难以预测。
用于同一任务的人工智能可以简单地参考有关该主题的文件并从以前的研究中得出结论。或者它可能会将新数据添加到组合中。也可以开始研究一个新的智能系统,完成最初的任务。
它可能不会在其他系统中上分心,但它清楚知道自己的方向。关键词是机器学习的大脑(智力)。虽然是人为的,但为了满足标准,它必须是真实的,从而产生类似于我们与周围其他人互动时遇到的变量和未知数。
机器学习和搜索引擎的关系
目前,搜索引擎(以及大多数科学家)正在推动发展的是机器学习。
谷歌有一个免费的 课程,已经开源了它的机器学习框架 TensorFlow ,并且正在对硬件进行大量投资来运行它。
这是未来,所以最好理解它。虽然我们不可能列出(甚至知道)在 Googleplex 上进行的所有机器学习应用,但让我们看几个已知的例子:
RankBrain
RankBrain系统具备对实体(单一、独特、明确定义和可区分的事物或概念)的理解,并负责理解这些实体如何在查询中连接,以帮助更好地理解查询和一组已知的好答案。谷歌向系统提供了一些数据(查询)和一组已知实体。然后系统的任务是根据实体的种子集自行训练如何识别它遇到的未知实体。
如果无法理解新电影的名称、日期等,该系统将毫无用处。一旦系统停止该过程并产生令人满意的结果,他们就会要求它自学如何理解实体之间的关系以及隐含或直接请求的数据,并在索引中寻找适当的结果。
这个系统解决了很多困扰谷歌的问题。不需要在有关更换屏幕的页面上包含诸如“如何更换我的 iphone 12 屏幕”之类的关键字进行搜索。如果您包含“替换”,您也不应该包含“修复”,因为在这种情况下,它们通常意味着相同的事情。
RankBrain 使用机器学习来:
- 不断了解实体的连通性及其关系。
- 了解单词什么时候是同义词,什么时候不是同义词(在这种情况下,替换和修复可能是同义词,但如果我询问“如何修理我的车”,它们就不会是同义词)。
- 指示算法的其他部分生成正确的 SERP。
在它的第一次迭代中,RankBrain 对谷歌以前没有遇到过的查询进行了测试。这是完全合理的,是一个很好的测试。如果 RankBrain 可以改进可能未优化的查询的结果,并且将涉及新旧实体和服务的混合,一组用户可能一开始就获得乏善可陈的结果,那么它应该在全球范围内部署。
可以看下这两个搜索结果的区别:
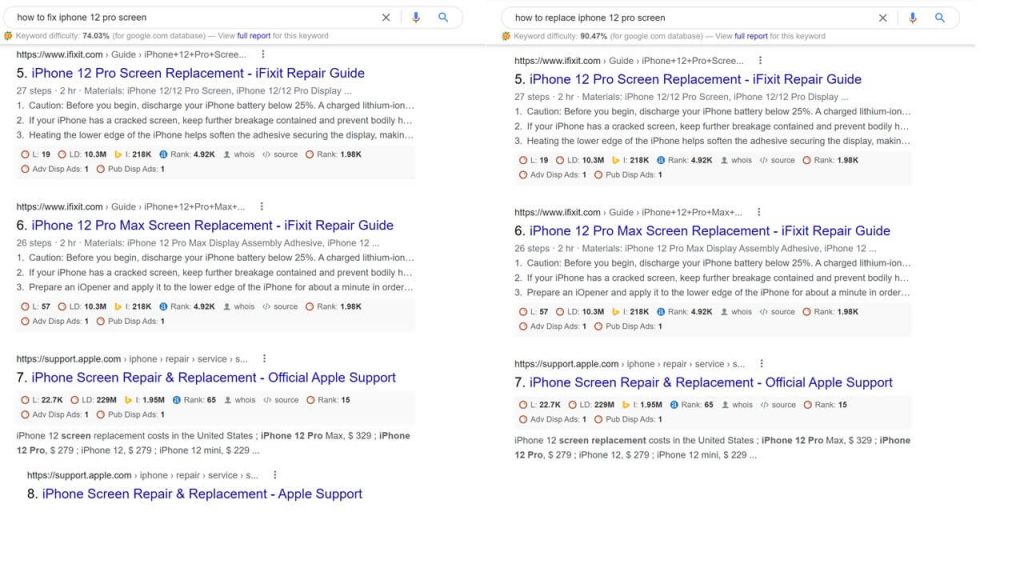
排名第 1 和第 2 的位置是相同的结果。
再来看一下我的汽车示例:
机器学习不仅帮助谷歌了解查询中的相似之处,而且我们还可以看到它确定是否我需要修理我的汽车,我可能需要一名修理师傅,而为了更换它,我可能指的是零件或者需要文件来替换整个事情。
我们还可以在这里看到机器学习还没有完全弄清楚的地方。当我问它如何更换我的汽车时,我可能是指整个事情,或者我会列出我想要的部分。
但它会继续学习,其实它仍处于起步阶段。
因此,在这里我们看到了一个机器学习在确定查询含义、SERP 布局和可能的必要行动方案以实现我的意图方面发挥作用的示例。并非所有这些都是 RankBrain,但都是机器学习。
Spam
我们使用的 Gmail 电子邮件系统,也会看到机器学习在发挥作用。
据谷歌称,他们现在阻止了 99.9% 的垃圾邮件和网络钓鱼电子邮件,误报率仅为 0.05%。
他们使用相同的核心技术来做这件事——给机器学习系统一些数据,然后让它去跑。
如果要手动对所有排列进行编程,以在垃圾邮件过滤中产生 99.9% 的成功率并动态调整以适应新技术,这对人工来说将是一项繁重的任务。
如果以人工的方式,那可能存在97% 的成功率和 1% 的误报(意味着 1% 的真实邮件被发送到垃圾邮件文件夹——如果这是重要的邮件,那肯定事无法接受的)。
继续进入机器学习 – 使用可以肯定确认的所有垃圾邮件进行设置,让它围绕它们的相似性建立模型,输入一些新消息并奖励它自己和随着时间的推移成功选择垃圾邮件,它会比人类学习更多的信号并做出更快的反应。
将其设置为监视用户与新电子邮件结构的交互,当它得知正在使用新的垃圾邮件技术时,将其添加到组合中,不仅过滤这些电子邮件,还过滤使用与垃圾邮件文件夹类似的技术的电子邮件。
那么机器学习是如何工作的呢?
这篇文章是对机器学习的解释,上面这些例子对于说明一个相当容易解释的模型是必要的。
其实它深层的逻辑或许很复杂,但我们需要知道的是比较简单。
常见的机器学习模型遵循以下顺序:
- 给系统一组已知数据。也就是说,一组具有大量可能变量的数据,这些变量与已知的正或负结果相关联。这用于训练系统并为其提供起点。基本上,它现在了解如何根据过去的数据识别和权衡因素以产生积极的结果。
- 设置成功的奖励。一旦系统以起始数据为条件,它就会被输入新数据,但没有已知的正面或负面结果。系统不知道新实体的关系或电子邮件是否为垃圾邮件。当它正确选择时,它会获得奖励(但显然不是一颗糖)。一个例子是给系统一个奖励值,目标是达到可能的最高数字。每次选择正确答案时,都会添加此分数。
- 放开它。一旦成功指标高到足以超越现有系统或达到另一个阈值,机器学习系统就可以与整个算法集成。
这个模型被称为监督学习,如果我的猜测是正确的,它就是大多数 Google 算法实现中使用的模型。
另一个模型是无监督模型。
借鉴 Coursera机器学习课程中使用的示例,这是用于在 Google 新闻中对类似故事进行分组的模型,可以推断它用于其他地方,例如识别和分组包含相同或谷歌图片中类似的人。
在这个模型中,系统不会被告知它在寻找什么,而是简单地指示按照相似的特征(它们包含的实体、关键字、关系、作者等)将实体(图像、文章等)分组到组中。
为什么了解机器学习很重要?
在这个互联网世界(或者是说现实世界中),越来越多的东西更智能化,而且更加依赖人工智能,确实它给我们的科技生活带来许多便利。
当我们在谷歌中键入搜索词时,如果出现的结果不是你想要的结果,就会令人沮丧。长期以来,机器学习一直是搜索引擎优化不可或缺的一部分。它不断帮助搜索引擎显示与搜索更相关的结果。它还有助于支持语音搜索服务、图像搜索和其他几个与搜索相关的功能。
建议阅读: