Google Search Console 的“页面索引报告”是帮助网站管理员了解网站在 Google 搜索结果中表现的重要工具。而许多网站管理员会发现,有些页面明明已经创建,却始终无法被 Google 索引,或者多次使用“验证工具”都无法解决该问题,这篇指南整理了中文搜索社区常见“网页未被编入索引”的原因,帮助网站管理员进一步了解产生错误的原因。
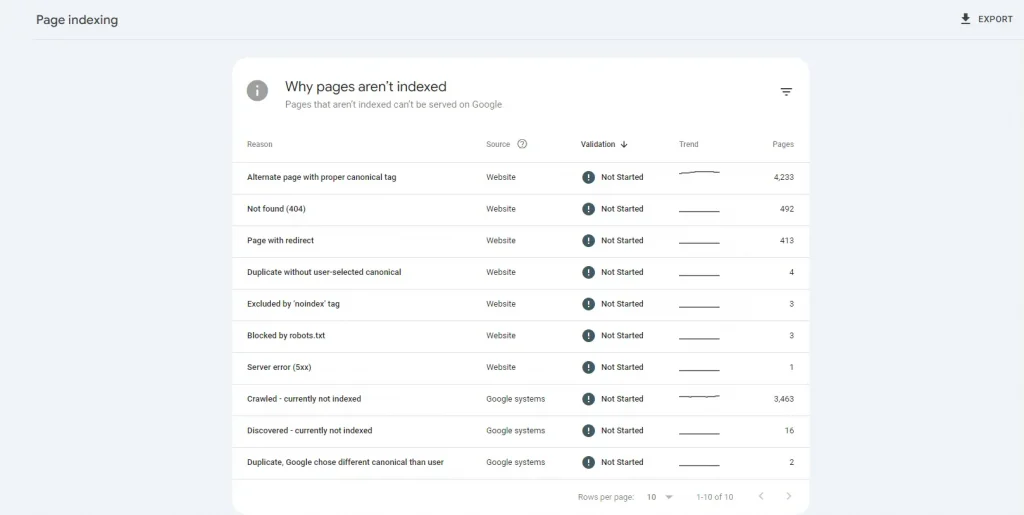
网站管理者可以通过“Google Search Console – 索引 – 网页索引”查看报告,里面则会列出每一条未被 Google 编入索引的 URLs,该板块列出了5个细分维度,分别是:
-
原因 – 某个网址无法编入索引的原因。
-
来源 – 表格中的来源值会显示问题的来源是 Google 还是网站。
-
验证 – 站长是否已请求验证此问题的修正效果。
-
趋势 – 影响网址的增幅情况。
- 页面数 – 影响网址的具体数量
这里需要重点讲解第2和3点,有时候显示的问题来源是 Google,不一定代表就是你无法解决的,例如“已抓取 – 当前未编入索引”和“已发现 – 目前未编入索引”也是站长们可以优化,这部分在下面的内容会介绍,而第三点,许多站长们都会直接点击“验证”按钮,但过段时间会发现,未索引的页面数并没减少(变化),这个功能需要谨慎使用,不要滥用导致 Google 不信任你的“调整”。接下来是我整理的 GSC 常见未被编入索引的原因:
已发现 – 目前未编入索引(Discovered – currently not indexed)
Google 已发现相应网页,但尚未抓取该网页。这通常意味着,Google 想要抓取该网址,但这样预计会导致网站过载;因此,Google 重新安排了抓取时间。这就是该网页的上次抓取日期在报告中为空的原因。——Google 官方解释
这表示,
- Google 发现了该页面;
- 但该页面可能存在一些问题,现已经在队列中,Google决定重新安排时间抓取;
已抓取 – 当前未编入索引(Crawled – currently not indexed)
Google 已抓取相应网页,但尚未将其编入索引。日后,该网页可能会被编入索引,也可能不会被编入索引;无论如何,您都无需重新提交该网址以供抓取。——Google 官方解释
这表示,
- Google 可以访问该页面;
- Google 花了一些时间来抓取页面;
- 爬取后,Google 决定不将其纳入索引;
导致上述的两种原因可能有,
- 抓取优先级
- 服务器性能
- 网站架构设置
- 网页内容价值
针对上述两种情况,网站管理者可以尝试,
- 内容质量问题——确保每个页面都包含唯一的内容。常见的低质量的页面有以下类型:过时的内容(如旧新闻文章),由网站内的搜索框生成的页面,通过应用过滤器生成的页面,重复内容,自动生成的内容,用户生成内容。最好通过Robots阻止此类页面。
- 内部链接问题——Googlebot 会跟踪您网站上的内部链接以发现其他页面并了解它们之间的联系。因此,请确保您最重要的页面经常在内部链接。
- 抓取预算——这种情况会出现在大型网站中,当页面数量超过百万,网站存在技术问题,容易造成抓取预算不足或浪费,常见抓取预算的问题有:低质量的内容, 内部链接结构差,实施重定向的错误,服务器超载等。
- 网站内部——确保提交给Google的XML站点地图中只有规范版本。
- 抓取优先级——给 Google 一些时间处理,因为有些页面可能只是在等待抓取。
重复网页 – Google 选择的规范网页与用户指定的不同(Duplicate, Google chose different canonical than user)
相应网页被标记为一组网页的规范网页,但 Google 认为另一网址更适合作为规范网页。Google 已将其认为是规范网页的那个网页(而非该网页)编入索引。——Google 官方解释
这表示,
- Google 在你的网站上发现了两个或多个相同或非常相似的网页;
- Google 抓取时发现了该网页的Canonical标签;
- Google 认为另一个网页更适合规范网页(系统评估);
- Google 忽视了该网页的规范标签,并决定不索引它;
导致上述的原因可能有,
- 网站出现对重复内容的指向信号(强烈)
重复网页 – 用户未选定规范网页(Duplicate without user-selected canonical)
相应网页与其他网页重复,但并未指明首选的规范网页。Google 已选择另一网页作为该网页的规范网页,因此该网页不会在 Google 搜索中显示。——Google 官方解释
这表示,
- Google 在你的网站上发现了两个或多个相同或非常相似的网页;
- Google 抓取时在页面上未发现canonical标签;
- Google 认为另一个网页更适合规范网页(系统评估);
- Google 决定不索引该页面;
导致上述的原因可能有,
- 多个重复/相似内容网页没有实施规范化
针对上述两种情况,网站管理者可以尝试,
- 确保rel=”canonical”链接仅在核心页面上实施;
- 增强网站核心页面内部信号(站点地图/内部链接);
网页会自动重定向(Page with redirect)
这是一个会重定向到另一网页的非规范网址。所以,该网址不会被编入索引。——Google 官方解释
这表示,
- Google抓取该网页时已被重定向至新页面;
- Google决定不索引该页面;
导致上述的原因可能有,
- 网站的链接结构调整
- 页面调整(例如产品下架,旧内容移除)
针对上述情况,网站管理者可以尝试,
- 检查这部分URL是否是正确/错误设置为重定向;
- 是 – 保留它;
- 不是 – 分析为何这部分页面会被设置为重定向,重定向逻辑制定错误?CMS内部错误?若查不到详细原因,可在文章中留下评论 或在 中文搜索社区进行提问。
已编入索引,尽管遭到 robots.txt 屏蔽(Indexed, though blocked by robots.txt)
该网页虽尽管遭到网站的 robots.txt 文件屏蔽,但已被编入索引。Google 始终都会遵从 robots.txt 中的规则,但如果有其他网页链接到该网页,这并不一定能够阻止该网页被编入索引。Google 不会请求和抓取该网页,但我们仍然可以使用与被屏蔽的网页关联的网页中的信息,将该网页编入索引。由于存在 robots.txt 规则,Google 搜索结果中显示的任何与该网页相关的摘要可能会非常有限。——Google 官方解释
这表示,
- Google从其他网页跟随并访问了该网页;
- Google评估该网页满足索引标准,决定索引该网页;
- 该网页在SERPs中显示非常有限;
导致上述的原因可能有,
- 内部/外部有存在指向该链接的信号
针对上述的情况,网站管理者可以尝试,
- 评估这部分 URL 是否真的应该被编入索引;
- 页面需要被索引 – 删除阻止抓取 URL 的 Disallow 指令;
- 页面不需要索引 – 不应使用 Robots.txt 来控制索引,请改用noindex 标记。
网址已被 robots.txt 屏蔽(Blocked by robots.txt)
此网页被网站的 robots.txt 文件屏蔽了。——Google 官方解释
这表示,
- Google遵循了该网站的robots设置;
- Google无法正常访问该网页;
导致上述的原因可能有,
- robots.txt 中的 Disallow 指令阻止了该网址
针对上述的情况,网站管理者可以尝试,
- 检查 robots 的 disallow 指令是有意还是错误地添加
- 有意的 – 保留它;
- 无意的 – 删除阻止抓取给定页面的 Disallow 指令。
Blocked due to access forbidden (403)( 由于禁止访问 (403) 而被屏蔽)
HTTP 403 表示用户代理提供凭据,但未被授予访问权限。不过,Googlebot 从未提供凭据,因此您的服务器错误地返回此错误。该网页不会被编入索引。——Google 官方解释
这表示,
- Google尝试抓取访问该网页;
- 由于网站服务器设置,拒绝了 Google 的访问请求;
导致上述的原因可能有,
- 网站服务器错误设置
针对上述的情况,网站管理者可以尝试,
- 联系主机服务商进行协助处理;
- 检查.htaccess 文件;
回到前面所说的,只有经过上述的调整后,网站管理者才可以在 GSC 中 点击“验证”按钮,而不是滥用该功能。以上是常见未被编入索引的情况,若没有列出的,可以参考 Google 官方文档